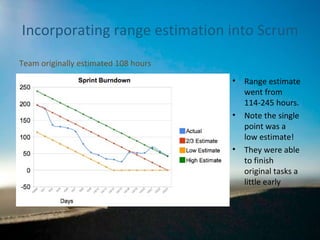
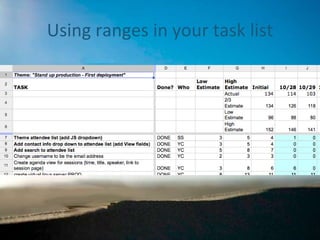
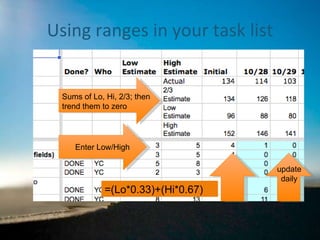
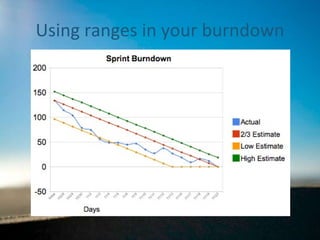
Range estimation in Scrum
Download as ppt, pdf3 likes2,549 views

The document discusses the implementation of range estimation in Scrum Agile to improve accuracy in project time estimation, highlighting the pitfalls of traditional single-point estimates. It emphasizes the significance of recognizing uncertainty and incorporating risk into project timelines, as well as the benefits of better communication through ranged estimates. Additionally, it addresses potential pitfalls of range estimation, such as credibility issues and the necessity of ensuring that stakeholders understand the value of these improved methods.
1 of 47
Downloaded 128 times
![Building a more accurate burndown Using Range Estimation in Scrum Agile 2010 Conference August 2010 Arin Sime 434 996 5226 [email_address]](https://image.slidesharecdn.com/rangeestimation-100804064906-phpapp01/85/Range-estimation-in-Scrum-1-320.jpg)



















![Why 2/3? Because it is both simple and pessimistic PERT does a similar thing: Expected = [BestCase + (4*MostLikely) + WorstCase] / 6 Source on PERT: Software Estimation , Steve McConnell, p109](https://image.slidesharecdn.com/rangeestimation-100804064906-phpapp01/85/Range-estimation-in-Scrum-32-320.jpg)










![Questions? Arin Sime 434 996 5226 [email_address] Twitter.com/ArinSime](https://image.slidesharecdn.com/rangeestimation-100804064906-phpapp01/85/Range-estimation-in-Scrum-47-320.jpg)
Ad
Recommended
Agile Software Estimation
Agile Software EstimationSunil Jakkaraju The document discusses agile software estimation, explaining what an estimate is, the factors influencing it, and various techniques used in agile projects such as planning poker. It highlights the importance of recognizing biases, avoiding commitment to estimates, and utilizing team-based approaches to improve accuracy. Key points include the significance of constant communication, relative estimation, and learning from past estimates to enhance future accuracy.
Agile estimation and planning peter saddington
Agile estimation and planning peter saddingtonPeter Saddington The document discusses several techniques for estimating the size and complexity of features in agile development projects, including planning poker, decomposition, and using ideal time vs elapsed time. It emphasizes that estimation in agile focuses on relative sizing rather than durations, and that estimates are intentionally vague at first and improve over time based on measuring team velocity. Key goals of iteration planning meetings are to set commitments and arrive at a prioritized backlog for the upcoming sprint.
Planning Poker
Planning Pokervineet Planning Poker is a technique used to estimate effort for tasks in Agile software development. It involves each team member privately selecting a planning poker card representing their estimate for a task. The cards have Fibonacci numbers written on them. The cards are then revealed and discussed if estimates differ, until consensus is reached. Once estimates are established, the team's velocity (amount of work completed per sprint) can be used to predict future release dates. Planning Poker works well because it leverages the wisdom of crowds and averages individual estimates for more accurate results.
Agile effort estimation
Agile effort estimation Elad Sofer This document discusses effort estimation in agile projects. It recommends estimating tasks by relative size using story points rather than absolute time values. Planning poker, where a team privately selects effort estimate cards and then discusses them, is advocated as it emphasizes relative estimation and reduces anchoring bias. Velocity, the number of points a team can complete per iteration, is key for planning and adjusting for estimation errors over time. Burn down charts also increase visibility of progress.
Agile Estimation Techniques
Agile Estimation TechniquesMikalai Alimenkou The document discusses agile estimation techniques, emphasizing the importance of estimating effort and duration in agile projects despite inherent inaccuracies. It advocates for team-based estimation methods, such as Planning Poker, to enhance decision-making, trust, and responsibility among team members. Key strategies include learning from past errors, practicing estimation, and classifying work rather than seeking precise estimates.
Agile estimation
Agile estimationStephen Forte The document discusses agile estimation and the challenges associated with traditional project estimation processes, highlighting how estimates can become rigid schedules that are resistant to change. It introduces agile estimation techniques, emphasizing the use of user stories, planning poker, and story points to provide relative size and complexity measures rather than time-based estimations. The presentation also covers the concept of team velocity and the importance of re-estimation after each sprint to accommodate evolving project details.
Software Project Estimation Survival Guide
Software Project Estimation Survival Guidemichaelcummings The document discusses project estimation, emphasizing the importance of accurate scope definition and customer involvement. It outlines practical steps for estimating, including the creation of mock-ups, team collaboration, and utilizing a work breakdown structure to manage tasks. The author highlights common pitfalls and stresses the need for clear communication and realistic time assessments to avoid project overruns.
Agile Planning and Estimation
Agile Planning and EstimationManish Agrawal, CSP® The document outlines the principles and methods of agile planning and estimation, emphasizing the importance of planning levels and the agile lifecycle. It discusses various estimating techniques, including relative and absolute estimating, and introduces the concept of story points to assess size and complexity. Additionally, it provides practical examples of user story estimation and the use of complexity buckets for categorizing work.
Estimating and planning Agile projects
Estimating and planning Agile projectsMurray Robinson The document discusses the challenges of estimating and planning agile projects, highlighting issues such as overly optimistic predictions and inadequate information. It outlines the importance of estimates for stakeholders to determine project feasibility and resource allocation. The discussion includes different estimation techniques, team velocity, planning poker, and the benefits of agile methodologies over traditional approaches.
Estimation techniques for Scrum Teams
Estimation techniques for Scrum TeamsJesus Mendez The document outlines a workshop series on estimation techniques for Agile Scrum teams, emphasizing the importance of collaborative estimation in software development. It covers various estimation methods, including absolute and relative estimation, and addresses the challenges faced during the estimation process, as well as the implications of the #noestimates movement. The workshop aims to enhance team performance and engagement by fostering shared understanding and effective communication around project estimations.
Agile estimates - Insights about the basic
Agile estimates - Insights about the basicDiogo S. Del Gaudio The document discusses the importance of agile estimation in project planning, highlighting how it can reduce risks and support better decision-making. It emphasizes the need for flexibility, collaboration, and incremental changes in an agile environment, while also addressing common planning failures such as overruns and prioritization issues. The concept of using story points and techniques like planning poker is presented as a way to improve estimation accuracy and team collaboration.
Agile estimating user stories
Agile estimating user storiesfungfung Chen User stories are estimated in story points to plan project timelines. Story points are a relative unit used to estimate complexity rather than time. The team estimates stories together by first independently assigning points, then discussing to converge on a shared estimate. Velocity is calculated based on the number of points completed in an iteration to predict future capacity. Pair programming may impact velocity but not the story point estimates themselves. Estimates should consider the story complexity and effort from the team perspective rather than individuals.
An introduction to agile estimation and release planning
An introduction to agile estimation and release planningJames Whitehead The document provides an introduction to agile estimation and release planning. It discusses building a product backlog by creating user stories, estimating each story using complexity buckets and points, and ensuring user stories meet INVEST criteria. It also covers splitting large user stories, acceptance criteria, and ensuring the product backlog is DEEP by being detailed, estimated, emergent, and prioritized. Estimation techniques include relative sizing to other stories and complexity buckets for different aspects like user interface, business logic, etc. The document emphasizes that estimation is about relative size rather than fixed timelines and that consistency is more important than absolute accuracy.
Is it a crime to estimate - #RSGECU2015
Is it a crime to estimate - #RSGECU2015Juliano Ribeiro This document discusses software development methodologies and estimating work. It provides biographical information about the author, including their experience in agile coaching and teaching. It then explores debates around estimating work, noting that estimates are not deadlines and focusing on understanding systems and accepting variability. Various estimation techniques are presented like planning poker, story points and lead time. A real case study example is shared how moving away from estimates to continuous delivery improved outcomes. The document emphasizes that #NoEstimates can work if work is done incrementally and rapidly to deliver value.
Agile Estimation
Agile EstimationSaltmarch Media The document discusses the challenges and techniques of agile estimation in project management, emphasizing the importance of iterative re-estimation and user story-based planning. It highlights common pitfalls in traditional estimation methods and introduces tools like planning poker and story points to improve accuracy and flexibility. The author, Stephen Forte, shares insights from his experience as a Chief Strategy Officer and agile practitioner, along with recommended readings on the topic.
Agile Scrum Estimation
Agile Scrum EstimationPrasad Prabhakaran The document discusses different approaches to estimation in waterfall and Scrum methodologies. In Scrum, teams estimate their own work in story points, which are relative units based on size and complexity. Story points help drive cross-functional behavior and do not decay over time. Ideal days estimates involve determining how long a task would take with ideal conditions and no interruptions. Planning poker uses story point cards to facilitate discussion and reach consensus on estimates. Release planning in Scrum involves estimating velocity over sprints to determine how many product backlog items can be completed.
Software management...for people who just want to get stuff done
Software management...for people who just want to get stuff doneCiff McCollum This document discusses concepts and techniques for software project management, including planning, estimation, execution, and retrospectives. It covers these concepts at the level of projects, milestones within projects, sprints, and individual stories. Key points emphasized include breaking work into small chunks, using techniques like planning poker and burndown charts, being honest about estimates, and using retrospectives to improve.
AgileChina 2015: Agile Estimation Workshop
AgileChina 2015: Agile Estimation WorkshopStephen Vance The Agile Estimation Workshop presented by Stephen Vance covers both opinion-based and empirical estimation techniques for Agile project management, emphasizing the importance of understanding team capacity, delivery forecasting, and progress reporting. Key topics include consensus-based estimation, story point velocity, team strength, and various statistical methods used for cycle time forecasting. The workshop also highlights the integration of visualization tools and confidence factors to enhance accuracy in project estimations.
Introduction to Agile Estimation & Planning
Introduction to Agile Estimation & PlanningAmaad Qureshi The document discusses estimation and planning in Agile methodologies, highlighting the importance of story points and various estimation techniques like planning poker. It emphasizes the need for relative measures of effort to improve accuracy and discusses how to estimate for tasks and plan iterations effectively. Additional resources for agile planning are also provided.
Agile 2010 Estimation Games
Agile 2010 Estimation GamesAgileCoach.net This document discusses techniques for software project estimation. It recommends providing estimates as ranges rather than specific numbers, and always clarifying what an estimate will be used for. It emphasizes aggregating independent estimates, using past project data to calibrate estimates, and not negotiating estimates or commitments. Key techniques include decomposing work into independently estimable units, using the "law of large numbers" for accuracy, and re-estimating regularly based on actual project velocity. Overall, the document provides guidance for creating estimates that are useful without being overly precise commitments.
Rise and fall of Story Points. Capacity based planning from the trenches.
Rise and fall of Story Points. Capacity based planning from the trenches.Mikalai Alimenkou The document discusses the limitations of using story points for sprint planning in Agile environments, highlighting issues like team specialization and the rationality of team members. It proposes a transition to capacity-based planning using hours as a more effective measure, advocating for personal responsibility and focused waste analysis. A capacity calculator is recommended to facilitate this new approach, ensuring better transparency and continuous improvement within teams.
Agile stories, estimating and planning
Agile stories, estimating and planningDimitri Ponomareff This document provides an overview of agile stories, estimating, and planning. It discusses what user stories are, how to write them, and techniques for estimating story sizes such as story points. It also covers different levels of planning including release planning, iteration planning, and daily planning. The document is intended to provide background information on using agile methods for requirements management and project planning.
Agile Projects | Rapid Estimation | Techniques | Tips
Agile Projects | Rapid Estimation | Techniques | TipscPrime | Project Management | Agile | Consulting | Staffing | Training The document describes a method called "Planning Poker" for quickly estimating project tasks through group discussion and iterative voting. A facilitator leads a team in estimating how many chickens are needed for a dinner party for 20 people. Through three rounds of voting and discussion to clarify assumptions, the team converges on an estimate of 13 chickens. Planning Poker aims to leverage collective expertise while avoiding biases from individual experts.
How to estimate in scrum
How to estimate in scrumGloria Stoilova - Story points are an arbitrary measure used by Scrum teams to estimate the effort required to implement a user story. Teams typically use a Fibonacci sequence like 1, 2, 3, 5, 8, 13, 20, 40, 100.
- Estimating user stories allows teams to plan how many highest priority stories can be completed in a sprint and helps forecast release schedules. The whole team estimates during backlog refinement.
- Stories are estimated once they are small enough to fit in a sprint and acceptance criteria are agreed upon. Teams commonly use planning poker where each member privately assigns a story point value and the team discusses until consensus is reached.
Estimation and Release Planning in Scrum
Estimation and Release Planning in ScrumLeapfrog Technology Inc. Scrum uses relative estimation and velocity to aid in planning and making trade-off decisions. Relative estimation involves comparing the effort of new requirements to previously estimated ones, which humans are better at than absolute estimates. Velocity is the amount of work completed in an iteration, measured in story points or hours, and varies over time so is useful for longer-term planning. There are two types of Scrum planning: fixed-date planning estimates how much can be completed by a date based on velocity, while fixed-scope planning estimates the timeframe to complete all backlog items based on velocity. Both use velocity as a range rather than a precise prediction.
Agile estimation and planning
Agile estimation and planning Elad Sofer This document discusses agile estimation and planning techniques. It recommends estimating tasks relatively using story points rather than absolute time estimates. Planning poker, where teams privately estimate tasks and then discuss estimates, is presented as an effective technique. Prioritizing a backlog by value, risk, and estimate allows teams to focus on the most important work. Iterative planning within sprints and tracking progress via burn down charts increases transparency.
Agile Estimating
Agile EstimatingRobert Dempsey The document discusses techniques for estimating work in Agile projects using story points and ideal days. It defines story points and ideal days, and explains how to assign estimates relatively by comparing stories rather than using specific units of time. The document also recommends estimating approaches like planning poker, re-estimating as stories change, and using the right units to keep estimates meaningful but relative.
Planning Poker estimating technique
Planning Poker estimating techniqueSuhail Jamaldeen Planning Poker is a consensus-based estimating technique used in agile software development methodologies like Scrum and Extreme Programming (XP). It involves a team estimating task lengths using cards displaying estimates in a Fibonacci sequence. The team discusses their estimates until reaching consensus, with the developer assigned the task having significant input. This engagement aims to create accurate estimates through discussion while avoiding one person influencing others.
Madhur Kathuria Release planning using feature points
Madhur Kathuria Release planning using feature pointsIndia Scrum Enthusiasts Community The document discusses various techniques for estimating work in Agile projects, including story points and feature points. It explains that story points are used to estimate user stories and provide a relative measure of complexity, while feature points are used to estimate larger features. The document also describes planning poker, where teams discuss estimates and converge on a shared value through discussion. Finally, it notes that estimates may need adjusting over time based on team experience and environment factors.
So when will it be done
So when will it be doneJohn Donoghue The document discusses agile estimating principles, emphasizing the importance of prioritizing the backlog and adjusting estimates as project understanding evolves. It addresses common challenges in software delivery, including the need for realistic commitments and managing stakeholder expectations regarding scope, cost, and timelines. Various scenarios illustrate how teams can manage changes in project estimates while communicating effectively with stakeholders.
More Related Content
What's hot (20)
Estimating and planning Agile projects
Estimating and planning Agile projectsMurray Robinson The document discusses the challenges of estimating and planning agile projects, highlighting issues such as overly optimistic predictions and inadequate information. It outlines the importance of estimates for stakeholders to determine project feasibility and resource allocation. The discussion includes different estimation techniques, team velocity, planning poker, and the benefits of agile methodologies over traditional approaches.
Estimation techniques for Scrum Teams
Estimation techniques for Scrum TeamsJesus Mendez The document outlines a workshop series on estimation techniques for Agile Scrum teams, emphasizing the importance of collaborative estimation in software development. It covers various estimation methods, including absolute and relative estimation, and addresses the challenges faced during the estimation process, as well as the implications of the #noestimates movement. The workshop aims to enhance team performance and engagement by fostering shared understanding and effective communication around project estimations.
Agile estimates - Insights about the basic
Agile estimates - Insights about the basicDiogo S. Del Gaudio The document discusses the importance of agile estimation in project planning, highlighting how it can reduce risks and support better decision-making. It emphasizes the need for flexibility, collaboration, and incremental changes in an agile environment, while also addressing common planning failures such as overruns and prioritization issues. The concept of using story points and techniques like planning poker is presented as a way to improve estimation accuracy and team collaboration.
Agile estimating user stories
Agile estimating user storiesfungfung Chen User stories are estimated in story points to plan project timelines. Story points are a relative unit used to estimate complexity rather than time. The team estimates stories together by first independently assigning points, then discussing to converge on a shared estimate. Velocity is calculated based on the number of points completed in an iteration to predict future capacity. Pair programming may impact velocity but not the story point estimates themselves. Estimates should consider the story complexity and effort from the team perspective rather than individuals.
An introduction to agile estimation and release planning
An introduction to agile estimation and release planningJames Whitehead The document provides an introduction to agile estimation and release planning. It discusses building a product backlog by creating user stories, estimating each story using complexity buckets and points, and ensuring user stories meet INVEST criteria. It also covers splitting large user stories, acceptance criteria, and ensuring the product backlog is DEEP by being detailed, estimated, emergent, and prioritized. Estimation techniques include relative sizing to other stories and complexity buckets for different aspects like user interface, business logic, etc. The document emphasizes that estimation is about relative size rather than fixed timelines and that consistency is more important than absolute accuracy.
Is it a crime to estimate - #RSGECU2015
Is it a crime to estimate - #RSGECU2015Juliano Ribeiro This document discusses software development methodologies and estimating work. It provides biographical information about the author, including their experience in agile coaching and teaching. It then explores debates around estimating work, noting that estimates are not deadlines and focusing on understanding systems and accepting variability. Various estimation techniques are presented like planning poker, story points and lead time. A real case study example is shared how moving away from estimates to continuous delivery improved outcomes. The document emphasizes that #NoEstimates can work if work is done incrementally and rapidly to deliver value.
Agile Estimation
Agile EstimationSaltmarch Media The document discusses the challenges and techniques of agile estimation in project management, emphasizing the importance of iterative re-estimation and user story-based planning. It highlights common pitfalls in traditional estimation methods and introduces tools like planning poker and story points to improve accuracy and flexibility. The author, Stephen Forte, shares insights from his experience as a Chief Strategy Officer and agile practitioner, along with recommended readings on the topic.
Agile Scrum Estimation
Agile Scrum EstimationPrasad Prabhakaran The document discusses different approaches to estimation in waterfall and Scrum methodologies. In Scrum, teams estimate their own work in story points, which are relative units based on size and complexity. Story points help drive cross-functional behavior and do not decay over time. Ideal days estimates involve determining how long a task would take with ideal conditions and no interruptions. Planning poker uses story point cards to facilitate discussion and reach consensus on estimates. Release planning in Scrum involves estimating velocity over sprints to determine how many product backlog items can be completed.
Software management...for people who just want to get stuff done
Software management...for people who just want to get stuff doneCiff McCollum This document discusses concepts and techniques for software project management, including planning, estimation, execution, and retrospectives. It covers these concepts at the level of projects, milestones within projects, sprints, and individual stories. Key points emphasized include breaking work into small chunks, using techniques like planning poker and burndown charts, being honest about estimates, and using retrospectives to improve.
AgileChina 2015: Agile Estimation Workshop
AgileChina 2015: Agile Estimation WorkshopStephen Vance The Agile Estimation Workshop presented by Stephen Vance covers both opinion-based and empirical estimation techniques for Agile project management, emphasizing the importance of understanding team capacity, delivery forecasting, and progress reporting. Key topics include consensus-based estimation, story point velocity, team strength, and various statistical methods used for cycle time forecasting. The workshop also highlights the integration of visualization tools and confidence factors to enhance accuracy in project estimations.
Introduction to Agile Estimation & Planning
Introduction to Agile Estimation & PlanningAmaad Qureshi The document discusses estimation and planning in Agile methodologies, highlighting the importance of story points and various estimation techniques like planning poker. It emphasizes the need for relative measures of effort to improve accuracy and discusses how to estimate for tasks and plan iterations effectively. Additional resources for agile planning are also provided.
Agile 2010 Estimation Games
Agile 2010 Estimation GamesAgileCoach.net This document discusses techniques for software project estimation. It recommends providing estimates as ranges rather than specific numbers, and always clarifying what an estimate will be used for. It emphasizes aggregating independent estimates, using past project data to calibrate estimates, and not negotiating estimates or commitments. Key techniques include decomposing work into independently estimable units, using the "law of large numbers" for accuracy, and re-estimating regularly based on actual project velocity. Overall, the document provides guidance for creating estimates that are useful without being overly precise commitments.
Rise and fall of Story Points. Capacity based planning from the trenches.
Rise and fall of Story Points. Capacity based planning from the trenches.Mikalai Alimenkou The document discusses the limitations of using story points for sprint planning in Agile environments, highlighting issues like team specialization and the rationality of team members. It proposes a transition to capacity-based planning using hours as a more effective measure, advocating for personal responsibility and focused waste analysis. A capacity calculator is recommended to facilitate this new approach, ensuring better transparency and continuous improvement within teams.
Agile stories, estimating and planning
Agile stories, estimating and planningDimitri Ponomareff This document provides an overview of agile stories, estimating, and planning. It discusses what user stories are, how to write them, and techniques for estimating story sizes such as story points. It also covers different levels of planning including release planning, iteration planning, and daily planning. The document is intended to provide background information on using agile methods for requirements management and project planning.
Agile Projects | Rapid Estimation | Techniques | Tips
Agile Projects | Rapid Estimation | Techniques | TipscPrime | Project Management | Agile | Consulting | Staffing | Training The document describes a method called "Planning Poker" for quickly estimating project tasks through group discussion and iterative voting. A facilitator leads a team in estimating how many chickens are needed for a dinner party for 20 people. Through three rounds of voting and discussion to clarify assumptions, the team converges on an estimate of 13 chickens. Planning Poker aims to leverage collective expertise while avoiding biases from individual experts.
How to estimate in scrum
How to estimate in scrumGloria Stoilova - Story points are an arbitrary measure used by Scrum teams to estimate the effort required to implement a user story. Teams typically use a Fibonacci sequence like 1, 2, 3, 5, 8, 13, 20, 40, 100.
- Estimating user stories allows teams to plan how many highest priority stories can be completed in a sprint and helps forecast release schedules. The whole team estimates during backlog refinement.
- Stories are estimated once they are small enough to fit in a sprint and acceptance criteria are agreed upon. Teams commonly use planning poker where each member privately assigns a story point value and the team discusses until consensus is reached.
Estimation and Release Planning in Scrum
Estimation and Release Planning in ScrumLeapfrog Technology Inc. Scrum uses relative estimation and velocity to aid in planning and making trade-off decisions. Relative estimation involves comparing the effort of new requirements to previously estimated ones, which humans are better at than absolute estimates. Velocity is the amount of work completed in an iteration, measured in story points or hours, and varies over time so is useful for longer-term planning. There are two types of Scrum planning: fixed-date planning estimates how much can be completed by a date based on velocity, while fixed-scope planning estimates the timeframe to complete all backlog items based on velocity. Both use velocity as a range rather than a precise prediction.
Agile estimation and planning
Agile estimation and planning Elad Sofer This document discusses agile estimation and planning techniques. It recommends estimating tasks relatively using story points rather than absolute time estimates. Planning poker, where teams privately estimate tasks and then discuss estimates, is presented as an effective technique. Prioritizing a backlog by value, risk, and estimate allows teams to focus on the most important work. Iterative planning within sprints and tracking progress via burn down charts increases transparency.
Agile Estimating
Agile EstimatingRobert Dempsey The document discusses techniques for estimating work in Agile projects using story points and ideal days. It defines story points and ideal days, and explains how to assign estimates relatively by comparing stories rather than using specific units of time. The document also recommends estimating approaches like planning poker, re-estimating as stories change, and using the right units to keep estimates meaningful but relative.
Planning Poker estimating technique
Planning Poker estimating techniqueSuhail Jamaldeen Planning Poker is a consensus-based estimating technique used in agile software development methodologies like Scrum and Extreme Programming (XP). It involves a team estimating task lengths using cards displaying estimates in a Fibonacci sequence. The team discusses their estimates until reaching consensus, with the developer assigned the task having significant input. This engagement aims to create accurate estimates through discussion while avoiding one person influencing others.
Agile Projects | Rapid Estimation | Techniques | Tips
Agile Projects | Rapid Estimation | Techniques | TipscPrime | Project Management | Agile | Consulting | Staffing | Training
Similar to Range estimation in Scrum (20)
Madhur Kathuria Release planning using feature points
Madhur Kathuria Release planning using feature pointsIndia Scrum Enthusiasts Community The document discusses various techniques for estimating work in Agile projects, including story points and feature points. It explains that story points are used to estimate user stories and provide a relative measure of complexity, while feature points are used to estimate larger features. The document also describes planning poker, where teams discuss estimates and converge on a shared value through discussion. Finally, it notes that estimates may need adjusting over time based on team experience and environment factors.
So when will it be done
So when will it be doneJohn Donoghue The document discusses agile estimating principles, emphasizing the importance of prioritizing the backlog and adjusting estimates as project understanding evolves. It addresses common challenges in software delivery, including the need for realistic commitments and managing stakeholder expectations regarding scope, cost, and timelines. Various scenarios illustrate how teams can manage changes in project estimates while communicating effectively with stakeholders.
Estimation Protips - NCDevCon 2014
Estimation Protips - NCDevCon 2014Jonathon Hill Jonathon Hill's presentation at NCDevCon discusses effective software estimation techniques, emphasizing that estimates should not be seen as promises and must account for inherent uncertainties. He outlines several pro tips for accurate estimations, including the dangers of premature estimation and the disadvantages of large teams. Additionally, he recommends using historical data for proxy estimations and stresses the importance of thorough planning to avoid pitfalls like scope creep and inflated time projections.
Software Estimation - part 1 of 2
Software Estimation - part 1 of 2Adi Dancu This document provides an overview of software project estimation. It defines what an estimate is, discusses characteristics of good estimates, and common sources of estimation inaccuracy. An estimate is a preliminary calculation, not an exact target or commitment. Good estimates have uncertainty ranges and probabilities attached. Estimates become more accurate as a project progresses and uncertainty decreases. Common causes of inaccurate estimates include unstable requirements, missing tasks, optimism bias, and subjective guessing. The document is part one of a two-part overview on software estimation best practices.
Improving Estimates
Improving EstimatesGiovanni Scerra ☃ This document provides guidance on improving estimates. It discusses expanding one's comfort zone to better understand related processes and people. Common estimation methods are outlined, including analogy, expert judgment, and task breakdown. The document emphasizes the importance of holistic, continuous estimation that considers risks, assumptions, and dependencies. It advises committing to estimates only when requirements are clear and risks are addressed, and avoiding arbitrary padding or unrealistic deadlines. Signs of poor estimates, like unreasonable assumptions or lack of deliverable definition, are identified as "estimate smells" to avoid.
Release planning using feature points
Release planning using feature pointsMadhur Kathuria The document discusses using feature points for agile release planning. It defines feature points and how they can be used to estimate user stories, features, and epics at different levels of a project. The key points are: feature points provide relative estimates independent of time units; epics are estimated by POs and architects, features by team leads, and stories by scrum teams; velocity is tracked in feature points to predict sprint and release completion; and principles for agile estimation emphasize basing estimates on facts, estimating often and small chunks, and communicating assumptions.
Ryan Ripley - The #NoEstimatesMovement
Ryan Ripley - The #NoEstimatesMovementProjectCon The document discusses the #NoEstimates movement in software development, which explores alternatives to traditional estimation practices. It notes that estimates often do not directly add value and the movement aims to reduce reliance on estimates or stop using them where possible. Key ideas include using story points instead of hours, limiting story sizes, and building cumulative flow diagrams to make decisions without estimates. The goal is to improve workflows so that estimates become unnecessary.
The art of estimation
The art of estimationKshitij Agrawal Estimating the size and effort required for projects and tasks is important for planning purposes but difficult to do with precision. Estimates are informed guesses that can vary due to factors like unclear requirements, lack of historical data, and scope changes. While estimates are not perfect, they provide value by enabling prioritization, collaboration, and iterative planning. Effective estimation techniques include using ranges rather than single points, factoring in assumptions, combining expert judgement with data-driven methods, and refining estimates over time as understanding improves.
Software estimation is crap
Software estimation is crapIan Garrison The document critiques the reliability of software estimates, highlighting their tendency to be significantly inaccurate due to complexities in software development compared to manufacturing. It discusses psychological factors affecting estimation and the detrimental effects of estimates on project management, such as mismanaged expectations and focus misalignment. Recommendations include using relative sizing, emphasizing feasibility, and shifting away from traditional estimation methods in favor of more adaptive planning approaches.
Estimates or #NoEstimates by Enes Pelko
Estimates or #NoEstimates by Enes PelkoBosnia Agile The document discusses the challenges and methodologies related to project estimation in software development, highlighting the issues of relying on estimates that often become commitments despite changing requirements. It introduces the #noestimates approach as a viable alternative to traditional estimation practices, advocating for agile principles that focus on delivering value and responding to real constraints rather than on estimating time and costs. Key topics include various estimation methods, common pitfalls, and advice for better estimating practices, ultimately calling for a shift in how teams approach project management.
Estimation
EstimationDev9Com This document discusses strategies for estimating software development project delivery. It will cover traditional and Agile techniques for estimation, including examining the purpose of estimates, differences between estimates and guarantees, and how estimation works in Scrum and Kanban environments. Attendees will learn about estimation strategies as a project manager or developer working with business partners.
When Will This Be Done?
When Will This Be Done?Rod Bray The document provides guidance on how to effectively answer the question of project completion timelines within agile projects, contrasting agile and traditional waterfall methodologies. It emphasizes the importance of understanding estimation realities, adopting probabilistic approaches, and recognizing cognitive biases that affect planning. The document advocates for a shift in focus from specific completion dates to wiser resource management and continuous refinement of estimates based on evolving project knowledge.
Esteem and Estimates (Ti Stimo Fratello)
Esteem and Estimates (Ti Stimo Fratello)Gaetano Mazzanti The document discusses issues with estimation in software projects. It notes that traditional estimation approaches fail because they ignore uncertainty and complexity. While Agile aims to help with lighter estimation practices, there is still risk of falling into the same traps as traditional methods. The key problems are how estimates are used, with unrealistic targets, imposed deadlines, and lack of respect causing issues. Respecting uncertainty and using estimates appropriately is emphasized as important.
Maximising Capital Investments - is guesswork eroding your bottomline?
Maximising Capital Investments - is guesswork eroding your bottomline?Michael McKeon The document discusses the significant impact of estimation bias on forecasting accuracy, leading to program failures and increased costs. It emphasizes the need for tools like reference class forecasting to mitigate these biases by focusing on past performance and using statistical methods. The document highlights that while optimism can aid in decision-making, balancing it with realism is crucial for better outcomes in project management.
Estimation Protips
Estimation ProtipsJonathon Hill The document provides estimation strategies and insights for software development, emphasizing that good estimates should be within 25% of actual results 75% of the time. Key advice includes avoiding premature estimation, understanding the cone of uncertainty, and using methodologies like decomposition and proxy estimation to improve accuracy. Additionally, it shares experiences and lessons learned from a case study involving an underestimated project, highlighting the importance of a thorough project scope and realistic estimates.
significance_of_test_estimating_in_the_software_development.pdf
significance_of_test_estimating_in_the_software_development.pdfsarah david The document discusses the significance of test estimation in software development, outlining its role in project planning, resource allocation, budgeting, risk management, and stakeholder communication. It details various estimation techniques such as work breakdown structure and agile methods, emphasizing the need for accurate estimates to optimize projects and enhance coordination. Best practices for effective test estimation are also provided, including understanding requirements, leveraging historical data, and ensuring regular updates throughout the project lifecycle.
Want better estimation ?
Want better estimation ?Alexandre Cuva The document discusses estimation techniques. It presents five estimation laws: 1) Don't estimate if you can measure, 2) compare instead of estimating units, 3) measure things that are measurable, 4) reduce precision of estimates based on knowledge, and 5) use different metrics for different estimates. Good practices discussed include using story sizing for requirements, measuring in hours for small tasks, using velocity, splitting large stories, and measuring fixed cycle times. The document provides resources for further learning about agile estimation techniques.
Software estimation techniques
Software estimation techniquesAndré Pitombeira The document discusses software estimation, emphasizing the challenges associated with making accurate estimates due to the complexity and uniqueness of software projects. It introduces concepts such as story points and estimation techniques like poker planning and affinity sizing, recommending relative measures over absolute ones. The document also explores the concept of sprint velocity as a measure of team progress and its calculation based on historical data.
[HCM Scrum Breakfast] Agile estimation - Story points
[HCM Scrum Breakfast] Agile estimation - Story pointsScrum Breakfast Vietnam This document provides information about agile estimation techniques, including story points and planning poker. It discusses how story points are used to provide relative estimates of complexity rather than time estimates. Planning poker is described as a consensus-based technique where a team privately selects story point cards before discussing to reach agreement. The document also covers insights around how additional details don't necessarily lead to better estimates and how past sprint performance can inform long-term planning estimates. Common questions about estimation techniques are addressed.
Dark Art of Software Estimation 360iDev2014
Dark Art of Software Estimation 360iDev2014Carl Brown The document discusses best practices for creating accurate software project estimates. It recommends estimating at the task level by breaking projects down into granular tasks. Thorough planning is important to generate reliable estimates. Other factors like team familiarity, task independence, and certainty of details can impact estimate quality. The document emphasizes that estimates are predictions and cannot predict the future with certainty.
Ad
More from OpenSource Connections (20)
Why User Behavior Insights? KMWorld Enterprise Search & Discovery 2024
Why User Behavior Insights? KMWorld Enterprise Search & Discovery 2024OpenSource Connections The document discusses the importance of user behavior insights in improving search functionality, noting that traditional search often fails to meet user needs due to its diverse applications and user requirements. It emphasizes the necessity of collecting and analyzing behavioral data to optimize search performance and recommends various testing and tuning techniques. Furthermore, it outlines the significance of a hybrid search configuration that effectively integrates multiple search methodologies based on user interactions.
Encores
EncoresOpenSource Connections This document discusses various search features beyond basic matching and ranking, including facets, query auto-completion, spelling correction, and query relaxation. It provides examples of how these features are implemented in Solr to help users formulate queries, understand results, and narrow down search outputs. Specific challenges with facets for e-commerce search are outlined, such as handling product variants and selecting the best facet values. Solutions proposed include indexing one document per variant, using collapse queries, and executing a prior facet request to select meaningful facets. The document also discusses approaches to auto-completion using suggesters and spelling correction using the Solr spellcheck component or alternative methods like fuzzy search over a query index. Finally, query relaxation techniques are briefly covered, such
Test driven relevancy
Test driven relevancyOpenSource Connections - Eric Pugh is the co-founder of OpenSource Connections, an Elasticsearch and Solr consultancy.
- OpenSource Connections helps clients improve their search relevance through consultancy, training, and community initiatives like meetups and conferences.
- Many websites have "broken" search relevance due to issues like poor collaboration, difficult testing processes, and slow iterations. OpenSource Connections aims to help clients address these issues through tools like their search dashboard Quepid.
- Improving search relevance is important for better conversion rates, understanding customer intent, and enabling personalization. OpenSource Connections provides strategies and services to help tune clients' search using frameworks, tools like Quepid, and a focus on measurement
How To Structure Your Search Team for Success
How To Structure Your Search Team for SuccessOpenSource Connections The document discusses structuring search teams for successful enterprise search and discovery, emphasizing the importance of people as a key component. It outlines a maturity model for search teams, detailing various roles and responsibilities needed to improve search performance and user experience. The content encourages understanding user needs, leveraging technology, and fostering collaboration among team members to enhance search capabilities.
The right path to making search relevant - Taxonomy Bootcamp London 2019
The right path to making search relevant - Taxonomy Bootcamp London 2019OpenSource Connections This document discusses improving search relevance. It notes that search quality has three aspects: relevance, performance, and experience. It emphasizes that improving relevance requires a cross-functional search team that is educated, empowered, and builds skills internally. It also stresses the importance of continuous measurement and refinement through metrics, instrumentation, and open source tools. The overall message is that achieving search relevance is as much a people problem as a technical one.
Payloads and OCR with Solr
Payloads and OCR with SolrOpenSource Connections The document discusses the integration of OCR technology using Tesseract and Tika with Solr to extract and index text from images for improved search relevance. It outlines challenges with highlighting matched text in images and introduces a payload component to surface payload attributes for matches, avoiding low-level hacks to Lucene. Future developments include enhancing the matches component to display matched terms, payload attributes, and additional index data.
Haystack 2019 Lightning Talk - The Future of Quepid - Charlie Hull
Haystack 2019 Lightning Talk - The Future of Quepid - Charlie HullOpenSource Connections Quepid is a search relevance dashboard and testing tool that is currently available as a $99/month hosted service. The company announced at a conference that Quepid will now be free to use as a hosted service and will soon be released as open source software. They are starting an open source community on GitHub and in a Slack channel to collaborate on the project and help drive broader adoption.
Haystack 2019 Lightning Talk - State of Apache Tika - Tim Allison
Haystack 2019 Lightning Talk - State of Apache Tika - Tim AllisonOpenSource Connections This document discusses Apache Tika, a tool for extracting text and metadata from various file formats. It describes how Tika works and some challenges that may occur such as exceptions, unsupported formats, or memory issues. The document also mentions a tool called tika-eval that profiles Tika runs and exceptions. Future plans for Tika include improved CSV, ZIP file parsing and detection as well as more modularized statistics collection and language identification.
Haystack 2019 Lightning Talk - Relevance on 17 million full text documents - ...
Haystack 2019 Lightning Talk - Relevance on 17 million full text documents - ...OpenSource Connections HathiTrust is a shared digital repository containing over 17 million scanned books from over 140 member libraries, totaling around 5 billion pages. It faces challenges in providing large-scale full-text search across this multilingual collection where document quality and structure varies. Initial approaches involved a two-tiered index but relevance must balance weights between full text and shorter metadata fields. Further tuning of algorithms like BM25 is needed to properly rank longer documents in the collection against metadata.
Haystack 2019 Lightning Talk - Solr Cloud on Kubernetes - Manoj Bharadwaj
Haystack 2019 Lightning Talk - Solr Cloud on Kubernetes - Manoj BharadwajOpenSource Connections This document discusses deploying Solr Cloud on Kubernetes. It notes that Kubernetes provides a universal language for deploying, configuring, and managing applications in the cloud or locally. Using Kubernetes can reduce costs and allow leveraging DevOps and SRE talent. However, deploying stateful applications like Solr Cloud on Kubernetes presents challenges related to managing stateful sets, configurations, persistent volumes, and cluster management. Questions are also raised around multi-zone configurations, pod replacement policies, and whether configurations are specific to certain cloud providers like AWS. Success stories are sought from users already deploying technologies like Zookeeper and Kafka on Kubernetes.
Haystack 2019 Lightning Talk - Quaerite a Search relevance evaluation toolkit...
Haystack 2019 Lightning Talk - Quaerite a Search relevance evaluation toolkit...OpenSource Connections This document introduces Quaerite, a search relevance toolkit for testing search relevance parameters offline. It allows running experiments to test different combinations of tokenizers, filters, scoring models and other parameters to evaluate search relevance without live user queries. The toolkit supports experimenting with all parameter permutations using grid search or random search, and also incorporates a genetic algorithm with cross-fold validation. It currently supports Apache Solr and plans to add support for ElasticSearch. The goal is to help optimize search relevance through offline testing of parameter configurations.
Haystack 2019 - Search-based recommendations at Politico - Ryan Kohl
Haystack 2019 - Search-based recommendations at Politico - Ryan KohlOpenSource Connections The document outlines a strategic approach to enhancing news recommendation systems, detailing various evaluation metrics and user engagement strategies. It discusses the complexities of developing a recommendation model, including user preferences, content filtering, and collaborative filtering techniques. Key challenges include system complexity, user feedback limitations, and the need for effective personalization to cater to dynamic user interests.
Haystack 2019 - Search with Vectors - Simon Hughes
Haystack 2019 - Search with Vectors - Simon HughesOpenSource Connections Simon Hughes, Chief Data Scientist at Dice.com, discusses the importance of high-quality content-based recommender engines for job matching in the tech industry. The document covers the challenges of semantic search, vector representations, and advanced NLP techniques, emphasizing the benefits of using deep learning models for better search results. Various methodologies, such as word embeddings and k-NN search, are explored to enhance the job search experience for candidates and employers.
Haystack 2019 - Natural Language Search with Knowledge Graphs - Trey Grainger
Haystack 2019 - Natural Language Search with Knowledge Graphs - Trey GraingerOpenSource Connections Trey Grainger's presentation covers natural language search using knowledge graphs, detailing the importance of understanding and utilizing semantic data in unstructured formats. He outlines the challenges of building traditional knowledge graphs and the methodologies to enhance query disambiguation through advanced analysis techniques. The document discusses the capabilities of Solr's semantic knowledge graph for real-time relationship traversal and scoring within various domains.
Haystack 2019 - Search Logs + Machine Learning = Auto-Tagging Inventory - Joh...
Haystack 2019 - Search Logs + Machine Learning = Auto-Tagging Inventory - Joh...OpenSource Connections John Berryman discusses the importance of automatic tagging in e-commerce search to enhance the customer experience and improve inventory categorization. He outlines various approaches to tagging, including curator involvement, content creator input, and customer contributions, while also presenting a machine learning-based method for leveraging search logs to create a tagging model. The presentation highlights challenges and potential improvements in tagging methods, the benefits of broader tags, and future directions for refining the process.
Haystack 2019 - Improving Search Relevance with Numeric Features in Elasticse...
Haystack 2019 - Improving Search Relevance with Numeric Features in Elasticse...OpenSource Connections The document discusses improving search relevance in Elasticsearch through the use of numeric features, focusing on distance, rank features, and vector fields. It outlines techniques for combining query-dependent textual scores with query-independent numeric features to enhance search results, including practical examples of searching for news articles and restaurants. Various queries are demonstrated, showcasing the optimization of search relevance by applying ranking and proximity functions.
Haystack 2019 - Architectural considerations on search relevancy in the conte...
Haystack 2019 - Architectural considerations on search relevancy in the conte...OpenSource Connections The document discusses architectural considerations for improving search relevance in e-commerce, highlighting the need for scalable solutions using tools like Google BigQuery and Elasticsearch. It outlines strategies for query standardization, ranking, and signal aggregation to enhance the search experience while addressing the benefits, limitations, and potential of the search relevance architecture. The conclusion suggests that further developments in query indexing can lead to additional features that improve user interaction.
Haystack 2019 - Custom Solr Query Parser Design Option, and Pros & Cons - Ber...
Haystack 2019 - Custom Solr Query Parser Design Option, and Pros & Cons - Ber...OpenSource Connections The document discusses the design and implementation of custom query parsers for Solr, including various strategies and the pros and cons of each approach. It highlights the need for custom query parsers when out-of-the-box options are insufficient for specific search requirements. The presentation at the Haystack conference provides insights into query parsing challenges, composition, and the development of a proximity query parser plugin.
Haystack 2019 - Establishing a relevance focused culture in a large organizat...
Haystack 2019 - Establishing a relevance focused culture in a large organizat...OpenSource Connections The document discusses strategies for establishing a relevance-focused culture within large organizations, detailing the role of various team members in improving search quality. It emphasizes the importance of tuning search engines through analysis, user feedback, and collaboration across disciplines. Key lessons include the need for a plan, early involvement, and creating a supportive community with effective tools.
Haystack 2019 - Solving for Satisfaction: Introduction to Click Models - Eliz...
Haystack 2019 - Solving for Satisfaction: Introduction to Click Models - Eliz...OpenSource Connections The document introduces click models and their relevance in measuring user satisfaction and interaction with search engine results. It outlines methods for defining event models, calculating probabilities of user actions, and evaluating model performance based on observed data. Key metrics discussed include click-through rates, conversion rates, and methods for estimating model parameters using probabilistic approaches.
Haystack 2019 Lightning Talk - Relevance on 17 million full text documents - ...
Haystack 2019 Lightning Talk - Relevance on 17 million full text documents - ...OpenSource Connections
Haystack 2019 Lightning Talk - Quaerite a Search relevance evaluation toolkit...
Haystack 2019 Lightning Talk - Quaerite a Search relevance evaluation toolkit...OpenSource Connections
Haystack 2019 - Search Logs + Machine Learning = Auto-Tagging Inventory - Joh...
Haystack 2019 - Search Logs + Machine Learning = Auto-Tagging Inventory - Joh...OpenSource Connections
Haystack 2019 - Improving Search Relevance with Numeric Features in Elasticse...
Haystack 2019 - Improving Search Relevance with Numeric Features in Elasticse...OpenSource Connections
Haystack 2019 - Architectural considerations on search relevancy in the conte...
Haystack 2019 - Architectural considerations on search relevancy in the conte...OpenSource Connections
Haystack 2019 - Custom Solr Query Parser Design Option, and Pros & Cons - Ber...
Haystack 2019 - Custom Solr Query Parser Design Option, and Pros & Cons - Ber...OpenSource Connections
Haystack 2019 - Establishing a relevance focused culture in a large organizat...
Haystack 2019 - Establishing a relevance focused culture in a large organizat...OpenSource Connections
Haystack 2019 - Solving for Satisfaction: Introduction to Click Models - Eliz...
Haystack 2019 - Solving for Satisfaction: Introduction to Click Models - Eliz...OpenSource Connections
Ad
Recently uploaded (20)
National Fuels Treatments Initiative: Building a Seamless Map of Hazardous Fu...
National Fuels Treatments Initiative: Building a Seamless Map of Hazardous Fu...Safe Software The National Fuels Treatments Initiative (NFT) is transforming wildfire mitigation by creating a standardized map of nationwide fuels treatment locations across all land ownerships in the United States. While existing state and federal systems capture this data in diverse formats, NFT bridges these gaps, delivering the first truly integrated national view. This dataset will be used to measure the implementation of the National Cohesive Wildland Strategy and demonstrate the positive impact of collective investments in hazardous fuels reduction nationwide. In Phase 1, we developed an ETL pipeline template in FME Form, leveraging a schema-agnostic workflow with dynamic feature handling intended for fast roll-out and light maintenance. This was key as the initiative scaled from a few to over fifty contributors nationwide. By directly pulling from agency data stores, oftentimes ArcGIS Feature Services, NFT preserves existing structures, minimizing preparation needs. External mapping tables ensure consistent attribute and domain alignment, while robust change detection processes keep data current and actionable. Now in Phase 2, we’re migrating pipelines to FME Flow to take advantage of advanced scheduling, monitoring dashboards, and automated notifications to streamline operations. Join us to explore how this initiative exemplifies the power of technology, blending FME, ArcGIS Online, and AWS to solve a national business problem with a scalable, automated solution.
vertical-cnc-processing-centers-drillteq-v-200-en.pdf
vertical-cnc-processing-centers-drillteq-v-200-en.pdfAmirStern2 מכונות CNC קידוח אנכיות הן הבחירה הנכונה והטובה ביותר לקידוח ארונות וארגזים לייצור רהיטים. החלק נוסע לאורך ציר ה-x באמצעות ציר דיגיטלי מדויק, ותפוס ע"י צבת מכנית, כך שאין צורך לבצע setup (התאמות) לגדלים שונים של חלקים.
FME for Good: Integrating Multiple Data Sources with APIs to Support Local Ch...
FME for Good: Integrating Multiple Data Sources with APIs to Support Local Ch...Safe Software Have-a-skate-with-Bob (HASB-KC) is a local charity that holds two Hockey Tournaments every year to raise money in the fight against Pancreatic Cancer. The FME Form software is used to integrate and exchange data via API, between Google Forms, Google Sheets, Stripe payments, SmartWaiver, and the GoDaddy email marketing tools to build a grass-roots Customer Relationship Management (CRM) system for the charity. The CRM is used to communicate effectively and readily with the participants of the hockey events and most importantly the local area sponsors of the event. Communication consists of a BLOG used to inform participants of event details including, the ever-important team rosters. Funds raised by these events are used to support families in the local area to fight cancer and support PanCan research efforts to find a cure against this insidious disease. FME Form removes the tedium and error-prone manual ETL processes against these systems into 1 or 2 workbenches that put the data needed at the fingertips of the event organizers daily freeing them to work on outreach and marketing of the events in the community.
FIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptx
FIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptxFIDO Alliance FIDO Seminar: Perspectives on Passkeys & Consumer Adoption
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...Edge AI and Vision Alliance For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/key-requirements-to-successfully-implement-generative-ai-in-edge-devices-optimized-mapping-to-the-enhanced-npx6-neural-processing-unit-ip-a-presentation-from-synopsys/
Gordon Cooper, Principal Product Manager at Synopsys, presents the “Key Requirements to Successfully Implement Generative AI in Edge Devices—Optimized Mapping to the Enhanced NPX6 Neural Processing Unit IP” tutorial at the May 2025 Embedded Vision Summit.
In this talk, Cooper discusses emerging trends in generative AI for edge devices and the key role of transformer-based neural networks. He reviews the distinct attributes of transformers, their advantages over conventional convolutional neural networks and how they enable generative AI.
Cooper then covers key requirements that must be met for neural processing units (NPU) to support transformers and generative AI in edge device applications. He uses transformer-based generative AI examples to illustrate the efficient mapping of these workloads onto the enhanced Synopsys ARC NPX NPU IP family.
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdf
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdfcaoyixuan2019 A presentation at Internetware 2025.
Securing Account Lifecycles in the Age of Deepfakes.pptx
Securing Account Lifecycles in the Age of Deepfakes.pptxFIDO Alliance Securing Account Lifecycles in the Age of Deepfakes
Crypto Super 500 - 14th Report - June2025.pdf
Crypto Super 500 - 14th Report - June2025.pdfStephen Perrenod This OrionX's 14th semi-annual report on the state of the cryptocurrency mining market. The report focuses on Proof-of-Work cryptocurrencies since those use substantial supercomputer power to mint new coins and encode transactions on their blockchains. Only two make the cut this time, Bitcoin with $18 billion of annual economic value produced and Dogecoin with $1 billion. Bitcoin has now reached the Zettascale with typical hash rates of 0.9 Zettahashes per second. Bitcoin is powered by the world's largest decentralized supercomputer in a continuous winner take all lottery incentive network.
OWASP Barcelona 2025 Threat Model Library
OWASP Barcelona 2025 Threat Model LibraryPetraVukmirovic Threat Model Library Launch at OWASP Barcelona 2025
https://owasp.org/www-project-threat-model-library/
Supporting the NextGen 911 Digital Transformation with FME
Supporting the NextGen 911 Digital Transformation with FMESafe Software Next Generation 911 involves the transformation of our 911 system from an old analog one to the new digital internet based architecture. The evolution of NG911 opens up a host of new opportunities to improve the system. This includes everything from device based location, to real time text. This can improve location accuracy dramatically as well as provide live updates from the citizen in need along with real time sensor updates. There is also the opportunity to provide multi-media attachments and medical records if the end user approves. This digital transformation and enhancements all require the support of new NENA and CRTC standards, along with integration across a variety of data streams.
This presentation will focus on how FME has supported NG911 transformations to date, and how we are positioning FME to support the enhanced capabilities to come. This session will be of interest to emergency services, municipalities and anyone who may be interested to know more about how emergency services are being improved to provide more accurate, localized information in order to improve the speed and relevance of emergency response and ultimately save more lives and provide better outcomes for those in need.
Bridging the divide: A conversation on tariffs today in the book industry - T...
Bridging the divide: A conversation on tariffs today in the book industry - T...BookNet Canada A collaboration-focused conversation on the recently imposed US and Canadian tariffs where speakers shared insights into the current legislative landscape, ongoing advocacy efforts, and recommended next steps. This event was presented in partnership with the Book Industry Study Group.
Link to accompanying resource: https://bnctechforum.ca/sessions/bridging-the-divide-a-conversation-on-tariffs-today-in-the-book-industry/
Presented by BookNet Canada and the Book Industry Study Group on May 29, 2025 with support from the Department of Canadian Heritage.
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...Edge AI and Vision Alliance For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/why-its-critical-to-have-an-integrated-development-methodology-for-edge-ai-a-presentation-from-lattice-semiconductor/
Sreepada Hegade, Director of ML Systems and Software at Lattice Semiconductor, presents the “Why It’s Critical to Have an Integrated Development Methodology for Edge AI” tutorial at the May 2025 Embedded Vision Summit.
The deployment of neural networks near sensors brings well-known advantages such as lower latency, privacy and reduced overall system cost—but also brings significant challenges that complicate development. These challenges can be addressed effectively by choosing the right solution and design methodology. The low-power FPGAs from Lattice are well poised to enable efficient edge implementation of models, while Lattice’s proven development methodology helps to mitigate the challenges and risks associated with edge model deployment.
In this presentation, Hegade explains the importance of an integrated framework that tightly consolidates different aspects of edge AI development, including training, quantization of networks for edge deployment, integration with sensors and inferencing. He also illustrates how Lattice’s simplified tool flow helps to achieve the best trade-off between power, performance and efficiency using low-power FPGAs for edge deployment of various AI workloads.
No-Code Workflows for CAD & 3D Data: Scaling AI-Driven Infrastructure
No-Code Workflows for CAD & 3D Data: Scaling AI-Driven InfrastructureSafe Software When projects depend on fast, reliable spatial data, every minute counts.
AI Clearing needed a faster way to handle complex spatial data from drone surveys, CAD designs and 3D project models across construction sites. With FME Form, they built no-code workflows to clean, convert, integrate, and validate dozens of data formats – cutting analysis time from 5 hours to just 30 minutes.
Join us, our partner Globema, and customer AI Clearing to see how they:
-Automate processing of 2D, 3D, drone, spatial, and non-spatial data
-Analyze construction progress 10x faster and with fewer errors
-Handle diverse formats like DWG, KML, SHP, and PDF with ease
-Scale their workflows for international projects in solar, roads, and pipelines
If you work with complex data, join us to learn how to optimize your own processes and transform your results with FME.
Kubernetes Security Act Now Before It’s Too Late
Kubernetes Security Act Now Before It’s Too LateMichael Furman In today's cloud-native landscape, Kubernetes has become the de facto standard for orchestrating containerized applications, but its inherent complexity introduces unique security challenges. Are you one YAML away from disaster?
This presentation, "Kubernetes Security: Act Now Before It’s Too Late," is your essential guide to understanding and mitigating the critical security risks within your Kubernetes environments. This presentation dives deep into the OWASP Kubernetes Top Ten, providing actionable insights to harden your clusters.
We will cover:
The fundamental architecture of Kubernetes and why its security is paramount.
In-depth strategies for protecting your Kubernetes Control Plane, including kube-apiserver and etcd.
Crucial best practices for securing your workloads and nodes, covering topics like privileged containers, root filesystem security, and the essential role of Pod Security Admission.
Don't wait for a breach. Learn how to identify, prevent, and respond to Kubernetes security threats effectively.
It's time to act now before it's too late!
The State of Web3 Industry- Industry Report
The State of Web3 Industry- Industry ReportLiveplex Web3 is poised for mainstream integration by 2030, with decentralized applications potentially reaching billions of users through improved scalability, user-friendly wallets, and regulatory clarity. Many forecasts project trillions of dollars in tokenized assets by 2030 , integration of AI, IoT, and Web3 (e.g. autonomous agents and decentralized physical infrastructure), and the possible emergence of global interoperability standards. Key challenges going forward include ensuring security at scale, preserving decentralization principles under regulatory oversight, and demonstrating tangible consumer value to sustain adoption beyond speculative cycles.
AI VIDEO MAGAZINE - June 2025 - r/aivideo
AI VIDEO MAGAZINE - June 2025 - r/aivideo1pcity Studios, Inc AI VIDEO MAGAZINE - r/aivideo community newsletter – Exclusive Tutorials: How to make an AI VIDEO from scratch, PLUS: How to make AI MUSIC, Hottest ai videos of 2025, Exclusive Interviews, New Tools, Previews, and MORE - JUNE 2025 ISSUE -
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdf
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdfMuhammad Rizwan Akram DC Inverter Air Conditioners are revolutionizing the cooling industry by delivering affordable,
energy-efficient, and environmentally sustainable climate control solutions. Unlike conventional
fixed-speed air conditioners, DC inverter systems operate with variable-speed compressors that
modulate cooling output based on demand, significantly reducing energy consumption and
extending the lifespan of the appliance.
These systems are critical in reducing electricity usage, lowering greenhouse gas emissions, and
promoting eco-friendly technologies in residential and commercial sectors. With advancements in
compressor control, refrigerant efficiency, and smart energy management, DC inverter air conditioners
have become a benchmark in sustainable climate control solutions
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptx
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptxFIDO Alliance FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography
FIDO Seminar: Authentication for a Billion Consumers - Amazon.pptx
FIDO Seminar: Authentication for a Billion Consumers - Amazon.pptxFIDO Alliance FIDO Seminar: Authentication for a Billion Consumers - Amazon
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...Edge AI and Vision Alliance
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...Edge AI and Vision Alliance
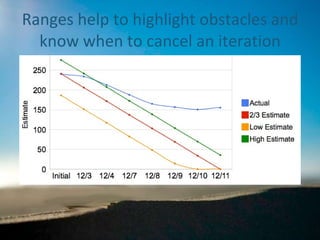
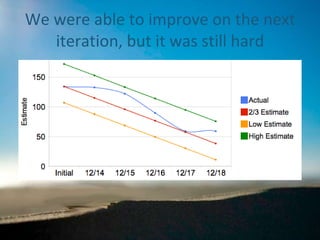
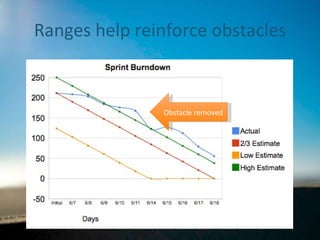
Range estimation in Scrum
- 1. Building a more accurate burndown Using Range Estimation in Scrum Agile 2010 Conference August 2010 Arin Sime 434 996 5226 [email_address]
- 2. Pitfalls of traditional estimation techniques
- 3. How long does it take you to get to work? traffic optimistic every day? method of travel
- 5. A little about me… Senior Consultant, OpenSource Connections in Charlottesville, Virginia Masters in Management of I.T., University of Virginia, McIntire School of Commerce We tweaked our Scrum process to incorporate Range Estimation based on my studies at Uva Please take the Estimation Survey: http://www.surveymonkey.com/s/SWNNYQJ
- 6. The root of all estimation evil: Single point estimates Chart taken from: Software Estimation , Steve McConnell, Figure 1-1, p6 “ A single-point estimate is usually a target masquerading as an estimate.” -Steve McConnell
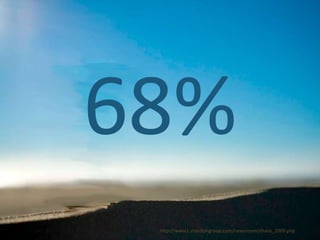
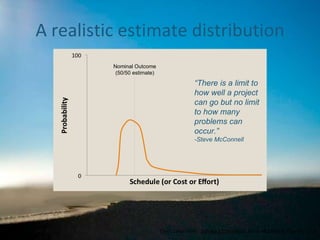
- 7. A realistic estimate distribution Chart taken from: Software Estimation , Steve McConnell, Figure 1-3, p8 “ There is a limit to how well a project can go but no limit to how many problems can occur.” -Steve McConnell Nominal Outcome (50/50 estimate)
- 8. Reasons we are wrong so often Different information Different methods Psychological Biases The Expert Problem
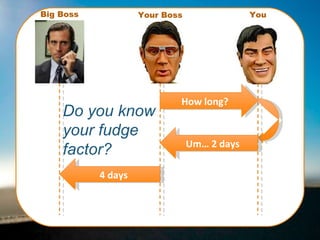
- 9. Bias in Estimation Imagine this scenario: “ Can you build me that CMS website in 2 weeks?” How would you respond? What estimate would you give?
- 10. Bias in Estimation By supplying my own estimate (or desire) in my question, I have anchored your response. This is called “The anchoring or framing trap” “ Because anchors can establish the terms on which a decision will be made, they are often used as a bargaining tactic by savvy negotiators.” From “The Hidden Traps in Decision Making” from Harvard Business Review, 1998, John Hammond, Ralph L. Keeney, and Howard Raiffa
- 11. You’re not as good as you think “ The Expert Problem” Experts consistently underestimate their margins of error, and discount the reasons they were wrong in the past. Excuses for past mistakes: You were playing a different game Invoke the outlier “ Almost right” defense The Black Swan: The impact of the Highly Improbable , by Nassim Nicholas Taleb, 2007, Chapter 10: The Scandal of Prediction
- 12. The best protection “ The best protection against all psychological traps – in isolation or in combination – is awareness.” From “The Hidden Traps in Decision Making” from Harvard Business Review, 1998, John Hammond, Ralph L. Keeney, and Howard Raiffa
- 14. How agile already avoids pitfalls Encourages team airing of estimates Done before assignment of tasks Scrum poker
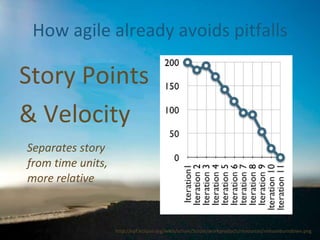
- 15. How agile already avoids pitfalls Separates story from time units, more relative Story Points & Velocity Image from: http://leadinganswers.typepad.com/leading_answers/2007/09/agile-exception.html
- 16. Agile and Scrum can run into other pitfalls though…
- 17. Potential pitfalls: Single-point estimates What about Risk? Implies a set delivery of features Story points are hard to explain
- 18. Better accuracy using range estimation
- 19. The Cone of Uncertainty http://www.construx.com/Page.aspx?hid=1648
- 20. Range estimation … Recognizes uncertainty Alleviates our tendency towards optimism Incorporates risk Allows for better financial projections Better informs our bosses and clients
- 21. Incorporating range estimation into Scrum
- 22. Incorporating range estimation into Scrum Team originally estimated 108 hours Range estimate went from 114-245 hours. Note the single point was a low estimate! They were able to finish original tasks a little early
- 23. Range estimation in Scrum Poker It’s very simple – just hold two cards instead of one! The same rules apply about creating discussion between low and high estimators, but you might resolve them differently...
- 24. On the high end Range estimation in Scrum Poker On the low end On the high end The likely discussion: Hey Orange, why do you say “2”? Yellow and Blue both say “5”. Likely Outcome: 3 or 5 Middle of the road
- 25. Range estimation in Scrum Poker Still middle of the road, but Green recognizes some risk Orange sees this as really easy Blue sees this as more complicated The likely discussion: Orange and Blue need to compare their visions for this task. Likely Outcome: 8-13? Red and Blue no longer agree: Red is confused or sees big risks
- 26. Using ranges in your task list
- 27. Using ranges in your task list Enter Low/High =(Lo*0.33)+(Hi*0.67) Sums of Lo, Hi, 2/3; then trend them to zero update daily
- 28. Using ranges in your burndown
- 29. Ranges help to highlight obstacles and know when to cancel an iteration
- 30. We were able to improve on the next iteration, but it was still hard
- 31. Ranges help reinforce obstacles Obstacle removed
- 32. Why 2/3? Because it is both simple and pessimistic PERT does a similar thing: Expected = [BestCase + (4*MostLikely) + WorstCase] / 6 Source on PERT: Software Estimation , Steve McConnell, p109
- 33. Using ranges to better communicate
- 34. Using range estimation to communicate risk Size of your range communicates the risk of your task May encourage you to break up tasks, or better define them. Scrum is all about better communication with the customer – so are ranges
- 35. How long? Um… 2 days 4 days Do you know your fudge factor? You Your Boss Big Boss
- 36. How long? 2-4 days 2-4 days Ranges help you control your fudge factor You Your Boss Big Boss
- 37. Another example: Use ranges to better empower your boss or client You Your Boss Big Boss
- 38. Perfect – Do it! How long? How much for X? GRRR Umm….. You Your Boss Big Boss 2 days Actually … 4 days 4 days later… 2 days * rate Budget Left: 2 days
- 39. Instead…. You Your Boss Big Boss
- 40. No thx, do something easier How long? How much for X? YES! You Your Boss Big Boss 2-4 days Done! 2 days later… 2-4 days * rate Budget Left: 2 days
- 41. Potential pitfalls of range estimation
- 42. Potential pitfalls of range estimation Really Wide Ranges Not everything can take 2 – 200 hours or you lose all credibility
- 43. Potential pitfalls of range estimation Bosses who don’t get it You’re going to have to sell them on how your estimates will improve their decision making ability.
- 44. Potential pitfalls of range estimation Pushed back deadlines Ranges are not an excuse to always miss deadlines. But they do make it less of a surprise, and encourage you to be more cautious.
- 45. Potential pitfalls of range estimation Is 2/3 the new single-point? Be careful not to just start treating the 2/3 calculated estimate, use the ranges.
- 46. Further Reading
- 47. Questions? Arin Sime 434 996 5226 [email_address] Twitter.com/ArinSime